【TIPS】PythonのSQLAlchemy使い方解説(SQLite/MySQL対応)

エンジニアライフスタイルブログを運営しているミウラ(@miumiu06171)です。
普段はフリーランスでシステムエンジニアをしております。
今回は、PythonのSQLAlchemyというデータベース(RDB)を扱うときに使うパッケージの基本的な使い方、およびSQLite3/MySQLを使った例を紹介しています。
本記事内のPythonコードは、Visual Studio Code (VS Code)で動作を確認しています。
同様に動作確認したい方は、こちらの記事を参照し、まずはVS Codeの環境構築をおこなってみてください。
SQLAlchemyとは
SQLAlchemyとは、Pythonで利用されるORM(Object Relational Mapping)の1つです。
ORMは、リレーショナルデータベース(RDB)とオブジェクト指向プログラミング間の違いを吸収してくれるライブラリのことで、SQL文を書かずにデータベースを簡単に操作できます。
SQLAlchemyの公式ドキュメントについては、こちらを参照ください。
SQLAlchemyのインストール
PythonでSQLAlchemyを扱うためには、以下のpipコマンドでsqlalchemyパッケージをインストールします。
| pip install sqlalchemy |
SQLAlchemyのチュートリアル
SQLAlchemyのチュートリアルを参照したい方は、公式サイトのこちらを参照してください。
このチュートリアルを簡略化し、実務に即役立つように基本的な使い方をこれから解説していきます。
SQLAlchemyの基本的な使い方
SQLAlchemyのインストールが完了したら、基本的な使い方をみてきましょう。
データベースのテーブルとフィールドを定義する
まずは、SQLAlchemyを使ってデータベースを扱うため、データベースのテーブルとフィールドを定義します。
例として下図のような学校の生徒を管理するためのデータベーステーブルを作ることを想定して説明していきます。
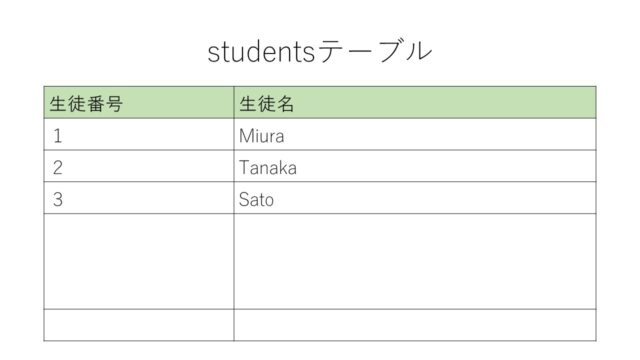
上記のような生徒番号と生徒名をフィールドに持つようなstudentsテーブルを、Pythonコードで定義すると、下記のようなPythonコードになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# sqlalchemyでデータベースのテーブルを扱うための宣言 Base = sqlalchemy.ext.declarative.declarative_base() # テーブルのフィールドを定義 class Student(Base): __tablename__ = 'students' id = sqlalchemy.Column( sqlalchemy.Integer, primary_key=True, autoincrement=True ) name = sqlalchemy.Column(sqlalchemy.String(30)) # データベースにテーブルを作成 Base.metadata.create_all(engine) |
テーブルを定義する
まず、データベースのテーブルは、上記PythonコードのStudentクラスのようにPythonのクラスで定義します。
そのとき、SQLとPythonのクラスの違いを吸収するため、PythonのクラスはSQLAlchemyのbaseクラスを継承する必要があります。
そして、テーブル名は、Pythonコードの6行目のように__tablename__変数に名前を指定すればオッケーです。
フィールドを定義する
次は、フィールドの定義をみていきましょう。
データベースのフィールドは、上記Pythonコードのid、nameのようにクラス変数で定義します。
そのとき、データベースのフィールドを示すためにsqlalchemyのColumnメソッドで定義する必要があります。
これだけで生徒番号を示すidと、生徒名を示すnameをフィールドに持つstudentsテーブルを定義できたことになります。
データベースへ接続するためのセッションを取得(session)
データベースを定義できたら、Pythonコードからデータベースにアクセスするためにセッションを取得する必要があります。
Pythonでデータベースへのセッションを取得するには、下記のようにPythonコードを記述します。
|
1 2 3 4 5 6 |
# エンジンの定義 engine = sqlalchemy.create_engine('sqlite:///:memory:') # データベースに接続するためのセッションを準備 Session = sqlalchemy.orm.sessionmaker(bind=engine) session = Session() |
セッションを取得するとき、まずどんな種類のデータベースにアクセスする予定なのかエンジンを指定します。
上記Pythonコードの例では、エンジンとして「’sqlite:///:memory:’」を指定し、sqliteのデータベースを指定しています。
「:memory:」の指定は、メモリ上にsqliteのデータベースを作ることを意味します。
つまり、外部ファイルにデータベースを記録せず、Pythonコードのプログラム実行中のみ使用し、プログラムが終了するとメモリ上のデータベースは消えます。
よって、開発中や動作確認するときによく使われますので、おぼえておきましょう。
テーブルのレコードを準備
セッションを取得できたところで、studentsテーブルは最初空であるため、テーブルに書き込むレコードを準備しましょう。
レコードを作るには、前述したStudentクラスのインスタンスを作ります。
下記Pythonコードでは、Studentクラスのインスタンスを3つ作り、生徒名を「Miura」、「Tanaka」、「Sato」としています。
|
1 2 3 4 5 6 7 |
# レコードを準備し、セッションを通してデータベースに送る s1 = Student(name='Miura') session.add(s1) s2 = Student(name='Tanaka') session.add(s2) s3 = Student(name='Sato') session.add(s3) |
このインスタンス生成時、生徒番号を示すidは、idフィールド定義時に「autoincrement=True」オプションが付いているため、自動的にidが割当たるようになっています。
Studentクラスのインスタンスが作れたら、セッションのaddメソッドを使ってインスタンスを追加します。
これでstudentsデータベースに書き込むレコードの準備は完了です。
データベースのテーブルにレコードを作成(Create)
レコードが準備できたので、実際にデータベースに書き込んでみましょう。
セッションのaddメソッドで追加したレコードを実際に書き込むには、下記Pythonコードのようにセッションのcommitメソッドを実行すると、データベースに書き込むことができます。
|
1 2 |
# データベースに送らたデータを実際に書き込む session.commit() |
データベースのテーブルのレコードを読み込み(Read)
次は、書き込んだレコードを読み込んでみましょう。
データベース内のレコードを読み込むには、セッションのqueryメソッドを使います。
queryメソッドの引数には、データベースのクラス名を指定します。
|
1 2 3 4 |
# データベースからテーブル情報を取得する students = session.query(Student).all() for student in students: print(student.id, student.name) |
そして、データベースのレコードをすべて取り出すため、queryのallメソッドを実行します。
その後、データベースの各レコードを表示するため、for文とprint文を使ってidとnameを表示しています。
データベースのテーブルのレコードを更新(Update)
次は、テーブルのレコードを更新してみましょう。
下記Pythonコードは、データベースのレコードのうち、生徒名が「Sato」であるレコードを取り出し、生徒名を「Suzuki」に変更する例です。
|
1 2 3 4 5 6 7 8 9 10 |
# 名前を更新する場合 s4 = session.query(Student).filter_by(name='Sato').first() s4.name = 'Suzuki' session.add(s4) session.commit() # データベースからテーブル情報を取得する students = session.query(Student).all() for student in students: print(student.id, student.name) |
データベースにqueryメソッドでアクセスし、filter_byメソッドで生徒名が「Sato」を検索してレコードを取り出します。
その後、取り出したレコードのnameフィールドを「Suzuki」に変更しています。
あとは、レコードを作成したときと同様にセッションのaddメソッドで追加し、commitメソッドでデータベースに変更内容を書き込んで更新しています。
データベースのテーブルのレコードを削除(Delete)
次は、テーブルのレコードを削除してみましょう。
下記Pythonコードは、生徒名が「Tanaka」のレコードを削除している例です。
|
1 2 3 4 5 6 7 8 9 10 |
# 名前を更新する場合 p5 = session.query(Student).filter_by(name='Tanaka').first() session.delete(p5) session.commit() # データベースからテーブル情報を取得する students = session.query(Student).all() for student in students: print(student.id, student.name) |
まず、削除する対象のレコードを取り出しますが、ここは前述のレコードの更新と同様にqueryのfilter_byメソッドでレコードを取り出します。
生徒名が「Tanaka」のレコードを取り出した後、セッションのdeleteメソッドで削除し、commitメソッドで実際にデータベースからも削除しています。
データベースのテーブル一覧を表示
データベースのテーブル一覧を表示するには、下記Pythonコードのようにqueryメソッドですべてのレコードを取り出した後、for文でレコード一覧を表示することができます。
|
1 2 3 4 |
# データベースからテーブル情報を取得する students = session.query(Student).all() for student in students: print(student.id, student.name) |
SQL文を確認する(echo=True)
前述してきたとおり、sqlalchemyを使うとSQL文を書けなくても、データベースにレコードを書き込んだり、更新したり、削除したりすることができました。
ここでは、sqlalchemyが内部的にどのようなSQL文を実行しているか確認するためのechoオプションを紹介します。
Pythonコードを実行中のSQL文を出力するためには、下記Pythonコードのようにエンジンの定義時の引数として「echo=True」というオプションを指定すればオッケーです。
|
1 2 |
# エンジンの定義 engine = sqlalchemy.create_engine('sqlite:///:memory:', echo=True) |
下図は、Pythonコードを実行したときのコンソール画面であり、最初に「Miura」、「Tanaka」、「Sato」を書き込んだとき、SQL文のINSERT INTO等が実行されていることがわかります。
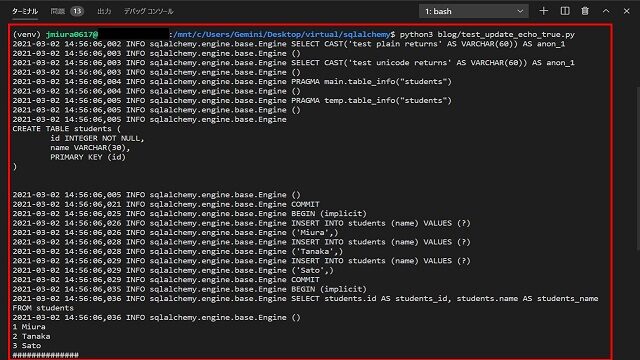
このように内部的に実行しているSQL文を確認することができます。
INSERT INTOなどのSQL文を忘れてしまった方は、こちらの記事に情報がまとまっていますので、復習にお使いいただければと思います。
SQLAlchemyのサンプルコードとCRUD処理
ここで示すSQLAlchemyのサンプルコードは、前述してきた一連の処理をまとめたものになります。
sqlite3を例にしたサンプルコードのため、pipコマンドでsqlite3をインストールした上で動作確認してみてください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
import sqlalchemy import sqlalchemy.ext.declarative import sqlalchemy.orm # エンジンの定義 engine = sqlalchemy.create_engine('sqlite:///:memory:', echo=True) # sqlalchemyでデータベースのテーブルを扱うための宣言 Base = sqlalchemy.ext.declarative.declarative_base() # テーブルのフィールドを定義 class Student(Base): __tablename__ = 'students' id = sqlalchemy.Column( sqlalchemy.Integer, primary_key=True, autoincrement=True ) name = sqlalchemy.Column(sqlalchemy.String(30)) # データベースにテーブルを作成 Base.metadata.create_all(engine) # データベースに接続するためのセッションを準備 Session = sqlalchemy.orm.sessionmaker(bind=engine) session = Session() # レコードを準備し、セッションを通してデータベースに送る s1 = Student(name='Miura') session.add(s1) s2 = Student(name='Tanaka') session.add(s2) s3 = Student(name='Sato') session.add(s3) # データベースに送らたデータを実際に書き込む session.commit() # データベースからテーブル情報を取得する students = session.query(Student).all() for student in students: print(student.id, student.name) print('##############') # 名前を更新する場合 s4 = session.query(Student).filter_by(name='Sato').first() s4.name = 'Suzuki' session.add(s4) session.commit() # データベースからテーブル情報を取得する students = session.query(Student).all() for student in students: print(student.id, student.name) print('##############') # レコードを削除する場合 s5 = session.query(Student).filter_by(name='Tanaka').first() session.delete(s5) session.commit() # データベースからテーブル情報を取得する students = session.query(Student).all() for student in students: print(student.id, student.name) |
上記Pythonコードでレコードの作成(Create)、読み出し(Read)、更新(Update)、削除(Delete)の一連の操作をマスターできれば、RDBを使ったWebアプリケーションの作成も容易になります。
なぜなら、Webアプリケーションの動作は、すべてこの4つの操作が基本になっているからです。
そして、Webアプリケーションの分野では、この4つの操作の頭文字をとって「CRUD処理」と呼ばれているので、併せておぼえておくとよいでしょう。
| ・C(Create) ・R(Read) ・U(Update) ・D(Delete) |
SQLAlchemyでSQLite3に接続して動作確認
ここでは、sqlite3のデータベースをメモリ上で扱うのではなく、実際に外部ファイルで扱う方法を紹介していきます。
SQLite3のインストール
まずは、sqlite3データベース本体をインストールしましょう。
Windowsの場合
sqlite3をインストールするには、まずこちらのダウンロードサイトへサクセスしてください。
サイト上に下図のようなリンクがありますので、「sqlite-tools-win32-x86-3340100.zip」をダウンロードしましょう。
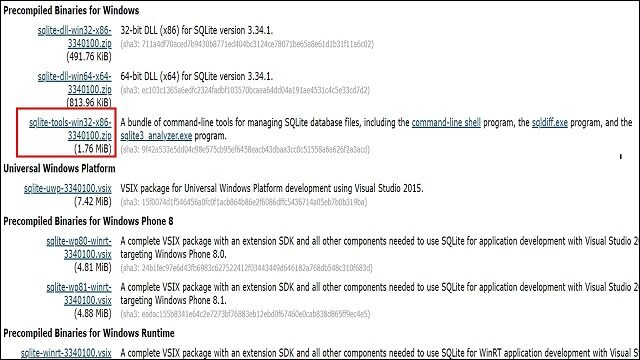
zipファイルを解凍後、解凍後のフォルダを任意の場所に移動し、パスを通したらオッケーです。
Linux(Ubuntu)の場合
当サイトと同じようにWSLを使ってWindows上でLinux(Ubuntu)を動かしている方は、以下のapt-getコマンドでインストールできます。
| sudo apt-get install sqlite3 |
pysqlite3をインストール
ここでは、Pythonコードから先程インストールしたsqlite3のデータベースにアクセスするためのpysqlite3パッケージをインストールします。
pysqlite3は、Pythonパッケージであるため、下記のようにpipコマンドでインストールします。
| pip install pysqlite3 |
Pythonコードのengineを修正
sqlite3本体とpysqlite3をインストールできたら、Pythonコードでsqlite3のデータベースを使うように修正していきます。
修正する箇所は、engineの定義部分の一箇所のみです。
sqlalchemyの使い方で説明したときのエンジン指定では、以下のようにPythonコードを実行中だけデータベースをメモリ上に作る指定をしていました。
【sqlite3のメモリを使う】
|
1 2 |
# エンジンの定義 engine = sqlalchemy.create_engine('sqlite:///:memory:') |
これを実際にsqlite3のデータベースとして外部ファイルに書き出して使うには、下記のようにエンジン指定の部分を変更する必要があります。
【sqlite3のデータベースを使う】
|
1 2 |
# エンジンの定義 engine = sqlalchemy.create_engine('sqlite:///test_sqlite.db', echo=True) |
「test_sqlite.db」は、sqlite3のデータベースの保存ファイル名であり、名前は任意で大丈夫です。
SQLite3データベースを使った動作確認
sqlite3のデータベースを使うようにエンジン指定部分を修正できたら、サンプルコードを実行して動作確認をしていきましょう。
下図は、サンプルコードを実行したときのコンソール画面になり、「echo=True」の設定であるため、内部で実行されているSQL文が確認でき、「Miura」「Tanaka」「Sato」がデータベースに作られていることが確認できます。
そして、「test_sqlite.db」というデータベースのファイルが出力されていればオッケーです。
SQLAlchemyでMySQLに接続して動作確認
ここでは、sqlite3のデータベースではなく、mysqlという別のデータベースで扱う方法を紹介します。
MySQLのインストール
まずは、MySQLのデータベース本体をインストールしていきましょう。
Windowsの場合
Windows上にMySQLをインストールする手順については、こちらの記事を参照してください。
インストールが完了したら、環境変数のパスにMySQLのインストール先を登録しておいてください。
パスが通ったら、管理者権限でコマンドプロンプトを起動し、下記の4つのコマンドでMySQLサーバーを起動してください。
| mysqld --install
mysqld -initialize net start mysql mysqld --skip-grant-tables |
MySQLサーバーを停止する場合は、下記のコマンドを実行してください。
| net stop mysql |
Linux(Ubuntu)の場合
当サイトと同じようにWSLを使ってWindows上でLinux(Ubuntu)を動かしている方は、以下のapt-getコマンドでインストールできます。
| sudo apt-get install mysql-server mysql-client |
セキュリティスクリプトを実行します。
| sudo mysql_secure_installation |
MySQLサーバーのサービスを起動します。
| systemctl start mysql |
UbuntuにMySQLをインストールする方法については、こちらの記事も参照ください。
また、MySQLの操作については、こちらの記事も参照ください。
pymysqlをインストール
ここでは、Pythonコードから先程インストールしたMySQLのデータベースにアクセスするためのpymysqlパッケージをインストールします。
pymysqlは、Pythonパッケージのインストールであるため、下記のようにpipコマンドでインストールします。
| pip install pymysql |
Pythonコードのengineを修正
MySQL本体とpymysqlをインストールできたら、PythonコードでMySQLのデータベースを使うように修正していきます。
sqlalchemyの使い方で説明したときのエンジン指定では、Pythonコード実行中だけデータベースをメモリ上に作る指定をしていました。
【sqlite3のメモリを使う】
|
1 2 |
# エンジンの定義 engine = sqlalchemy.create_engine('sqlite:///:memory:') |
これをMySQLのデータベースとして外部ファイルに書き出して使うには、下記のようにエンジン指定の部分を変更する必要があります。
|
1 2 |
# エンジンの定義 engine = sqlalchemy.create_engine('mysql+pymysql:///test_mysql.db', echo=True) |
「test_mysql.db」は、MySQLのデータベースの保存ファイル名であり、名前は任意で大丈夫です。
MySQLデータベースを使った動作確認
MySQLのデータベースを使うようにエンジン指定部分を修正できたら、サンプルコードを実行して動作確認をしていきましょう。
sqlite3のときと同様に確認することができます。
まとめ
いかがでしたでしょうか。
多くのアプリケーションでは、データベースを使ってデータ管理をしていて今や必須技術と言ってもいいと思います。
そのような必須技術にも関わらず、PythonのSQLAlchemyを使えば、SQL文を覚える必要もなく、簡単にデータベースを操作できることがわかってもらえたと思います。
そして、データベースにはSQLite、MySQL、PostgreSQL等の複数種類がある中、SQLAlchemyで開発していれば、エンジン指定でデータベースの種類を指定するだけで色々なデータベースが扱えて移植性が高いことがわかりましたね。
SQLAlchemyがサポートしているデータベースの詳細については、こちらに掲載されています。
SQLAlchemyは、とても便利なパッケージであるため、活用頂ければ幸いです。





