【TIPS】データ分析ならコレ!Python Pandas使い方まとめ(DataFrame編)

エンジニアライフスタイルブログを運営しているミウラ(@miumiu06171)です。
普段はフリーランスでシステムエンジニアをしております。
今回は、こちらの前回記事に引き続いて、Pythonでデータ分析の支援を行うPandasのDataFrame(データフレーム)の操作をまとめて紹介していきます。
なお、本記事内のPythonソースコードは、JupyterLabで動作を確認しているので、同様に動作確認したい方はこちらの記事も参照し、まずはJupyterLabの環境構築をおこなってください。
DataFrameを作成する
PandasのDataFrameを作成する方法を紹介してきます。
リスト型で作る
リスト型でDataFrameを作成するには、以下のように記述します。
【Pythonコード】
二次元リストでDataFrameを作成している例です。
|
1 2 3 |
df = pd.DataFrame( [[1,2,3], [4,5,6], [7,8,9]] ) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

カラム名指定(columns)
DataFrameにカラム名を付ける方法を紹介します。
【Pythonコード】
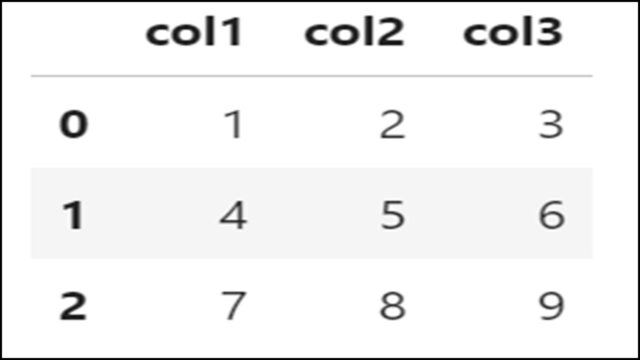
DataFrameのカラム名として、「col1」「col2」「col3」を指定している例です。
|
1 |
df.columns = ['col1', 'col2', 'col3'] |
【表示結果】
上記Pythonコードで変更したDataFrameを表示すると、以下のようになります。
インデックス名指定(index)
DataFrameにインデックス名を付ける方法を紹介します。
【Pythonコード】
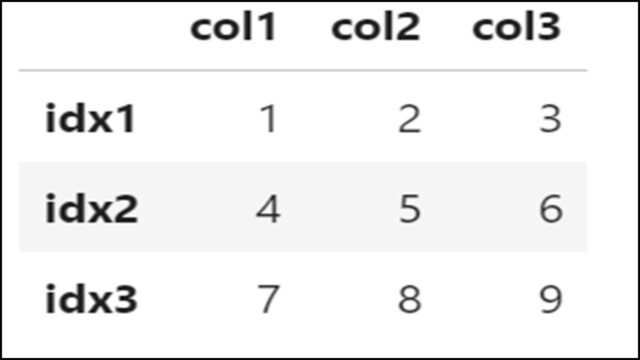
DataFrameのインデックス名として、「idx1」「idx2」「idx3」を指定している例です。
|
1 |
df.index = ['idx1', 'idx2', 'idx3'] |
【表示結果】
上記Pythonコードで変更したDataFrameを表示すると、以下のようになります。

カラム名、インデックス名を一括指定
DataFrameにカラム名、インデックス名を一括で付ける方法を紹介します。
【Pythonコード】
columns引数、index引数にそれぞれカラム名、インデックス名を指定することで一括で指定することができます。
|
1 2 3 4 5 |
df = pd.DataFrame( [[1,2,3], [4,5,6], [7,8,9]], columns=['col1', 'col2', 'col3'], index=['idx1', 'idx2', 'idx3'] ) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
辞書型で作る
辞書型でDataFrameを作成するには、以下のように記述します。
【Pythonコード】
Key・Valueの辞書型でDataFrameを作成している例です。
|
1 2 3 4 5 |
df = pd.DataFrame( {'col1': [1,2,3], 'col2': [4,5,6], 'col3': [7,8,9] }) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
インデックス名を指定(index)
DataFrameにインデックス名を付ける方法を紹介します。
【Pythonコード】
DataFrameのインデックス名として、「idx1」「idx2」「idx3」を指定している例です。
|
1 |
df.index = ['idx1', 'idx2', 'idx3'] |
【表示結果】
上記Pythonコードで変更したDataFrameを表示すると、以下のようになります。
カラム名、インデックス名を一括指定
DataFrameにカラム名、インデックス名を一括で付ける方法を紹介します。
【Pythonコード】
index引数にインデックス名を指定することで一括で指定することができます。
|
1 2 3 4 5 6 |
df = pd.DataFrame( {'col1': [1,2,3], 'col2': [4,5,6], 'col3': [7,8,9] }, index = ['idx1', 'idx2', 'idx3']) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
numpyで作る
numpyでDataFrameを作成するには、以下のように記述します。
【Pythonコード】
numpyのarrayメソッドを使ってDataFrameを作成している例です。
|
1 2 3 4 5 |
import numpy as np df = pd.DataFrame( np.array([[1,2,3], [4,5,6], [7,8,9]]), ) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
カラム名指定(columns)
DataFrameにカラム名を付ける方法を紹介します。
【Pythonコード】
List型でカラム名を指定するときと同様です。
|
1 |
df.columns = ['col1', 'col2', 'col3'] |
インデックス名指定(index)
DataFrameにインデックス名を付ける方法を紹介します。
【Pythonコード】
List型でインデックス名を指定するときと同様です。
|
1 |
df.index = ['idx1', 'idx2', 'idx3'] |
カラム名、インデックス名を一括指定
DataFrameにカラム名、インデックス名を一括で付ける方法を紹介します。
【Pythonコード】
List型でカラム名、インデックス名を一括で指定するときと同様です。
|
1 2 3 4 5 |
df = pd.DataFrame( np.array([[1,2,3], [4,5,6], [7,8,9]]), columns=['col1', 'col2', 'col3'], index=['idx1', 'idx2', 'idx3'] ) |
CSVファイルで作る
CSVファイルからDataFrameを作成するには、以下のように記述します。
【CSVファイル】
|
1 2 3 |
1,2,3 4,5,6 7,8,9 |
【Pythonコード】
「test.csv」からDataFrameを作成している例です。
|
1 |
df_csv = pd.read_csv('test.csv', encoding='SHIFT-JIS') |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

「1, 2, 3」の部分がDataFrameのデータではなく、ヘッダーとして読み込まれているので、うまく読み込めていません。
後述しているヘッダーの設定を元に使い方を見ていきましょう。
CSVファイル内にヘッダーがある場合
CSVファイル内にヘッダーがある場合には、以下のように記述します。
【Pythonコード】
「header=0」を指定することで、1行目のデータをヘッダーとして取り込んでいます。
|
1 |
df_csv = pd.read_csv('test.csv', encoding='SHIFT-JIS', header=0) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
「header=0」はデフォルトであるため、「header=0」つけないときと同じ結果になっています。
CSVファイル内にヘッダーがない場合
CSVファイル内にヘッダーがない場合には、以下のように記述します。
【Pythonコード】
「header=None」を指定することで、ヘッダーなしとしてデータを取り込んでいます。
|
1 |
df_csv = pd.read_csv('test.csv', encoding='SHIFT-JIS', header=None) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
CSVファイルのすべてのデータを、DataFrameのデータ部分に取り込めていることがわかります。
カラム名指定
DataFrameにカラム名を付ける方法を紹介します。
【Pythonコード】
names引数でカラム名をつけることができます。
|
1 |
df_csv = pd.read_csv('test.csv', encoding='SHIFT-JIS', header=None, names=['col1', 'col2', 'col3']) |
【表示結果】
上記PythonコードでDataFrameを表示すると、以下のようになります。
インデックス名指定
DataFrameにインデックス名を付ける方法を紹介します。
【Pythonコード】
|
1 2 |
df_csv = pd.read_csv('test.csv', encoding='SHIFT-JIS', header=None, names=['col1', 'col2', 'col3']) df_csv.index = ['idx1', 'idx2', 'idx3'] |
【表示結果】
上記PythonコードでDataFrameを表示すると、以下のようになります。
DataFrameのデータを取得する
DataFrameのデータを取得する方法を色々紹介していきます。
DataFrame全体を取得
DataFrame全体を取得するには、以下のように記述します。
【Pythonコード】
DataFrame全体を取得するには、print文で取得することができます。
|
1 2 3 4 5 6 7 |
df = pd.DataFrame( [[1,2,3], [4,5,6], [7,8,9]], columns=['col1', 'col2', 'col3'], index=['idx1', 'idx2', 'idx3'] ) print(df) |
【表示結果】
上記PythonコードでDataFrameを表示すると、以下のようになります。
カラムを取得
DataFrameのカラムを取得する方法を紹介していきます。
series型でカラム取得
Series型でカラムを取得するには、以下のように記述します。
【Pythonコード】
「col1」というカラムデータをSeries型で取得する例です。
|
1 |
df['col1'] |
【表示結果】
上記PythonコードでDataFrameを表示すると、以下のようになります。

【Pythonコード】
type関数で出力される型を確認している例です。
|
1 |
type(df['col1']) |
上記Pythonコードで実行すると、Series型であることがわかります。
|
1 |
pandas.core.series.Series |
DataFrame型でカラム取得
DataFrame型でカラムを取得するには、以下のように記述します。
【Pythonコード】
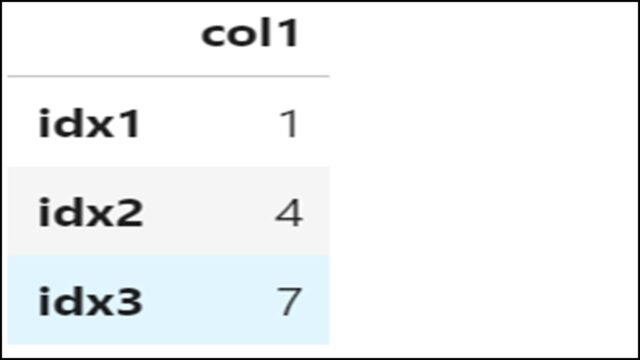
「col1」というカラムデータをDataFrame型で取得する例です。
|
1 |
df[['col1']] |
【表示結果】
上記PythonコードでDataFrameを表示すると、以下のようになります。
【Pythonコード】
type関数で出力される型を確認している例です。
|
1 |
type(df[['col1']]) |
上記Pythonコードで実行すると、DataFrame型であることがわかります。
|
1 |
pandas.core.frame.DataFrame |
locでカラム名を指定して取得
カラム名を指定してカラムを取得するには、locメソッドを使用します。
【Pythonコード】
「col1」というカラムデータを取得する例です。
|
1 |
df.loc[:, 'col1'] |
【表示結果】
上記PythonコードでDataFrameを表示すると、以下のようになります。

【Pythonコード】
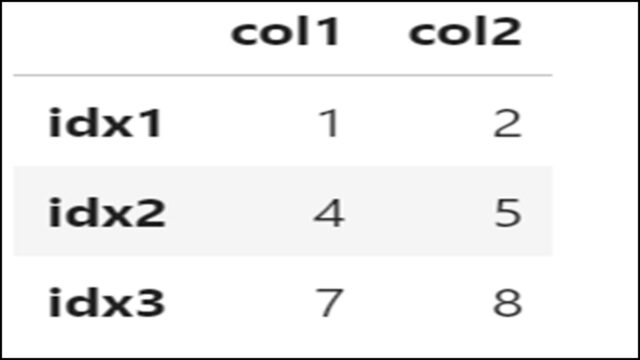
スライスを使って連続する複数カラムを取得することもできます。
|
1 |
df.loc[:, 'col1':'col2'] |
【表示結果】
「col1」から「col2」の複数カラムを取得していることがわかります。
ilocでカラム番号を指定して取得
カラム番号を指定してカラムを取得するには、ilocメソッドを使用します。
【Pythonコード】
カラム番号が0のカラムデータを取得する例です。
|
1 |
df.iloc[:, 0] |
【表示結果】
カラム番号が0(「col1」)のカラムデータを取得していることがわかります。
【Pythonコード】
スライスを使って連続する複数カラムを取得することもできます。
|
1 |
df.iloc[:, 0:2] |
【表示結果】
カラム番号が0から2未満(「col1」から「col2」)の複数カラムを取得していることがわかります。
インデックスを取得
DataFrameのインデックスを取得する方法を紹介していきます。
locでインデックス名を指定して取得
インデックス名を指定してインデックスを取得するには、locメソッドを使用します。
【Pythonコード】
「idx1」というインデックスデータを取得する例です。
|
1 |
df.loc['idx1'] |
【表示結果】
上記PythonコードでDataFrameを表示すると、以下のようになります。

【Pythonコード】
スライスを使って連続する複数インデックスを取得することもできます。
|
1 |
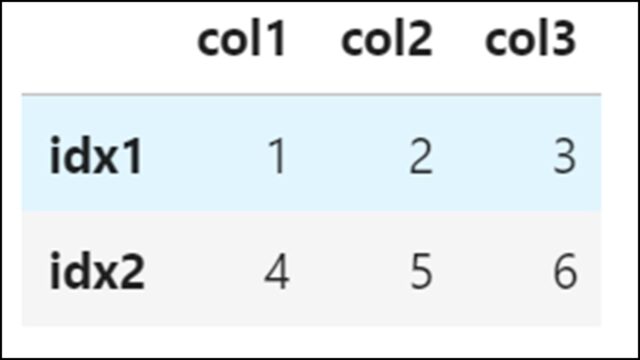
df.loc['idx1':'idx2'] |
【表示結果】
「idx1」から「idx2」の複数インデックスを取得していることがわかります。
ilocでインデックス番号を指定して取得
インデックス番号を指定してインデックスを取得するには、ilocメソッドを使用します。
【Pythonコード】
インデックス番号が0(「idx1」)のインデックスデータを取得する例です。
|
1 |
df.iloc[0] |
【表示結果】
インデックス番号が0(「idx1」)のインデックスデータを取得していることがわかります。
【Pythonコード】
スライスを使って連続する複数インデックスを取得することもできます。
|
1 |
df.iloc[0:2] |
【表示結果】
インデックス番号が0から2未満(「idx1」から「idx2」)の複数インデックスを取得していることがわかります。
最初の数行(head)
DataFrameの最初の数行を表示するには、以下のheadメソッドを使用します。
【Pythonコード】
|
1 |
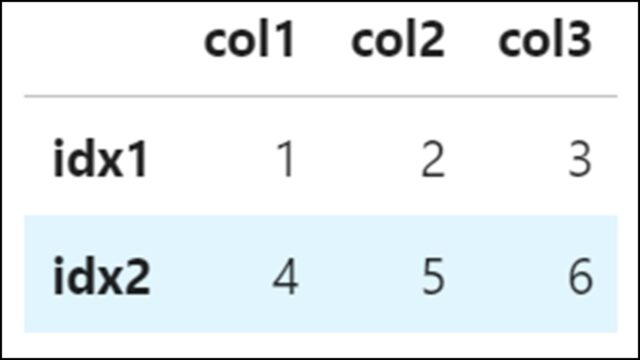
df.head(2) |
上記のコードは、DataFrameの最初の2行を表示している例です。
【表示結果】
最後の数行(tail)
DataFrameの最後の数行を表示するには、以下のtailメソッドを使用します。
【Pythonコード】
|
1 |
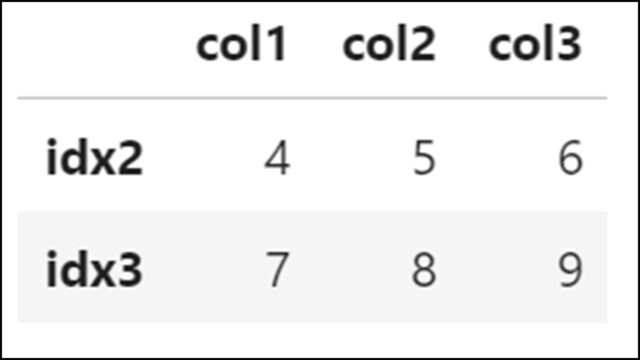
df.tail(2) |
【表示結果】
任意の数行(sample)
DataFrameの中の任意の数行を表示するには、以下のsampleメソッドを使用します。
【Pythonコード】
|
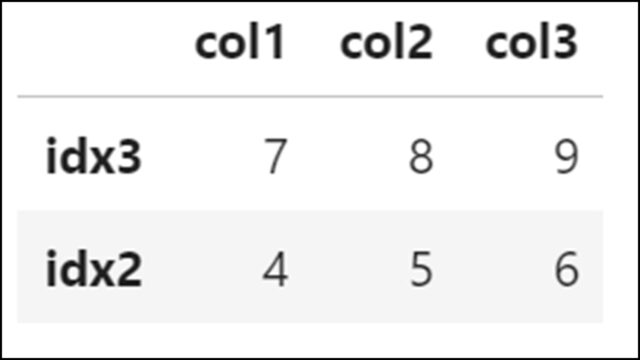
1 |
df.sample(2) |
【表示結果】
DataFrameの基本情報を確認する
DataFrameの色々な基本情報を確認する方法を紹介していきます。
基本情報確認(info)
DataFrameの基本情報を確認するには、以下のように記述します。
【Pythonコード】
|
1 |
df.info() |
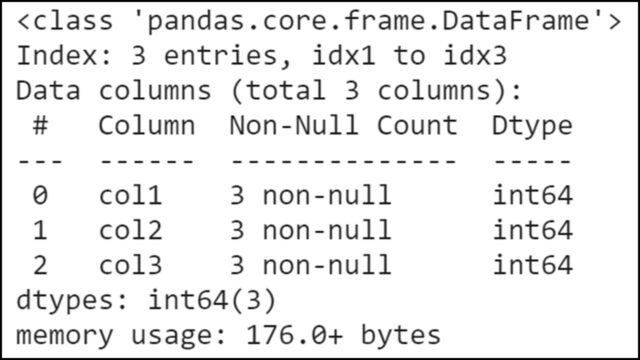
【表示結果】
インデックスが「idex1」から「idx3」までの3つのインデックス、「col1」から「col3」まで3つのカラムで構成されることがわかります。
また、「col1」から「col3」までのカラムのそれぞれのデータ型がint64であることがわかります。
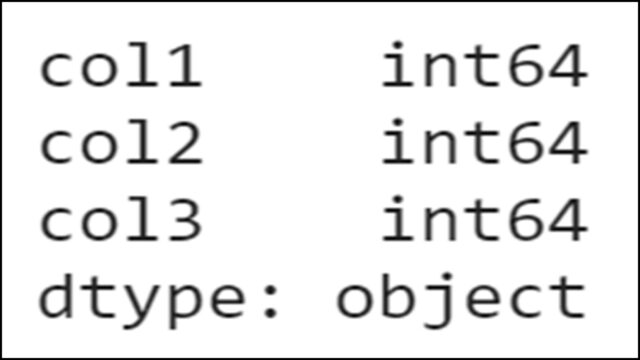
各カラムの型を一覧表示(dtypes)
各カラムの型を一覧表示するには、以下のようにdtypesを使用します。
【Pythonコード】
|
1 |
df.dtypes |
【表示結果】
カラムのそれぞれのデータ型が表示されることがわかります。
カラム数を取得(columns)
カラム数を取得するには、以下のようにcolumnsを使用します。
【Pythonコード】
|
1 |
print(df.columns) |
【表示結果】
|
1 |
RangeIndex(start=0, stop=3, step=1) |
インデックス数を取得(index)
インデックス数を取得するには、以下のようにindexを使用します。
【Pythonコード】
|
1 |
print(df.index) |
【表示結果】
|
1 |
RangeIndex(start=0, stop=3, step=1) |
カラム数とインデックス数を確認(shape)
カラム数とインデックス数を確認するには、「shape」を使用します。
【Pythonコード】
|
1 2 3 4 5 6 7 |
df = pd.DataFrame( [[1,2,3], [4,5,6], [7,8,9]], columns=['col1', 'col2', 'col3'], index=['idx1', 'idx2', 'idx3'] ) print(df.shape) |
【表示結果】
(行数, 列数)のようにDataFrameの大きさを確認することができます。
|
1 |
(3, 3) |
インデックス番号を確認(index.get_loc)
インデックス名からインデックス番号を確認するには、「index.get_loc」メソッドを使用します。
【Pythonコード】
|
1 2 3 4 5 6 7 |
df = pd.DataFrame( [[1,2,3], [4,5,6], [7,8,9]], columns=['col1', 'col2', 'col3'], index=['idx1', 'idx2', 'idx3'] ) print(df.index.get_loc('idx2')) |
【表示結果】
インデックス名が「idx2」のインデックス番号は「1」であることがわかります。
|
1 |
1 |
カラム番号を確認(columns.get_loc)
カラム名からカラム番号を確認するには、「columns.get_loc」メソッドを使用します。
【Pythonコード】
|
1 2 3 4 5 6 7 |
df = pd.DataFrame( [[1,2,3], [4,5,6], [7,8,9]], columns=['col1', 'col2', 'col3'], index=['idx1', 'idx2', 'idx3'] ) print(df.columns.get_loc('col3')) |
【表示結果】
カラム名が「col3」のカラム番号は「2」であることがわかります。
|
1 |
2 |
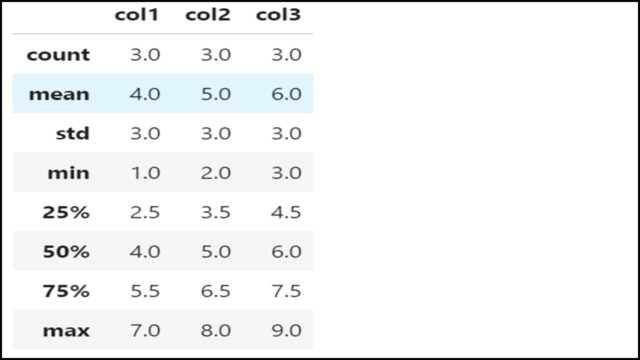
統計量確認(describe)
DataFrameの統計量を確認するには、以下のようにdescribeメソッドを使用します。
【Pythonコード】
|
1 |
df.describe() |
【表示結果】
カラムごとの数、平均値、標準偏差、最小値、25/50/75パーセント分位数、最大値を確認することができます。
DataFrameの基本情報を変更する
DataFrameの基本情報を変更する方法を紹介していきます。
カラム名を変更
カラム名を変更する2通りの方法を紹介します。
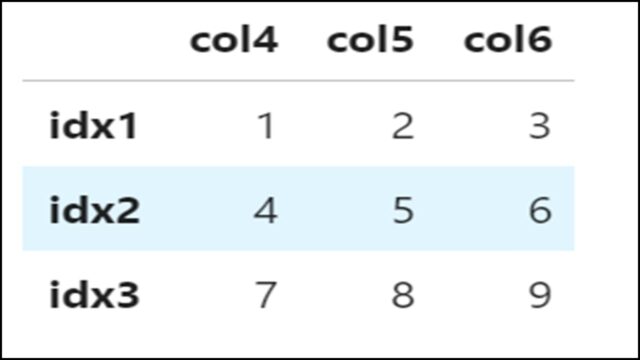
すべてのカラム名を変更する(columns)
すべてのカラム名を変更するには、以下のようにcolumnsを使用します。
【Pythonコード】
|
1 2 3 4 5 6 7 |
df = pd.DataFrame( [[1,2,3], [4,5,6], [7,8,9]], columns=['col1', 'col2', 'col3'], index=['idx1', 'idx2', 'idx3'] ) df.columns = ['col4', 'col5', 'col6'] |
【表示結果】
カラム名が「col1」「col2」「col3」から「col4」「col5」「col6」に変更されていることがわかります。
一部のカラム名を変更する(rename)
一部のカラム名を変更するには、以下のようにrenameを使用します。
【Pythonコード】
|
1 2 3 |
df = df.rename( columns = {'col4': 'x'} ) |
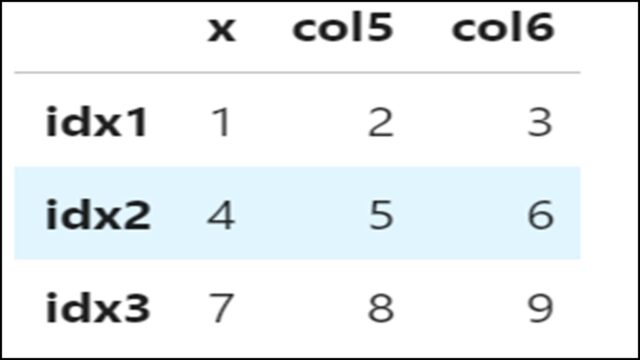
【表示結果】
カラム名が「col1」から「x」に変更されていることがわかります。
【Pythonコード】
|
1 2 3 |
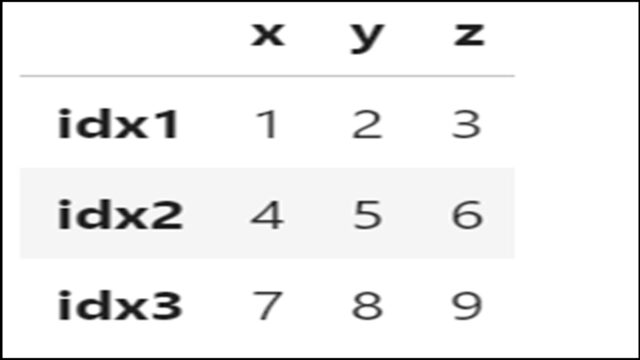
df = df.rename( columns = {'col5': 'y', 'col6': 'z'} ) |
【表示結果】
カラム名が「col2」「col3」から「y」「z」に変更されていることがわかります。
インデックス名を変更
インデックス名を変更する2通りの方法を紹介します。
すべてのインデックス名を変更する(index)
すべてのインデックス名を変更するには、以下のようにindexを使用します。
【Pythonコード】
|
1 2 3 4 5 6 7 |
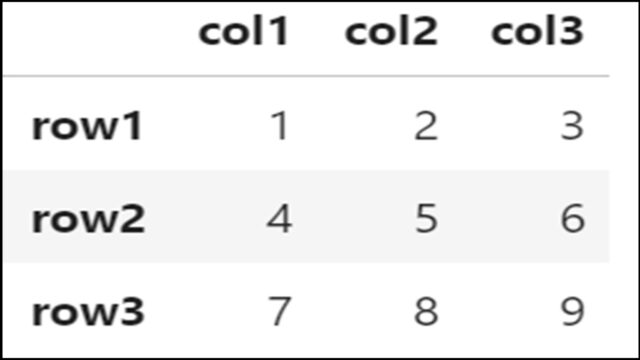
df = pd.DataFrame( [[1,2,3], [4,5,6], [7,8,9]], columns=['col1', 'col2', 'col3'], index=['idx1', 'idx2', 'idx3'] ) df.index = ['row1', 'row2', 'row3'] |
【表示結果】
インデックス名が「idx1」「idx2」「idx3」から「row1」「row2」「row3」に変更されていることがわかります。
一部のインデックス名を変更する(rename)
一部のインデックス名を変更するには、以下のようにrenameを使用します。
【Pythonコード】
|
1 2 3 |
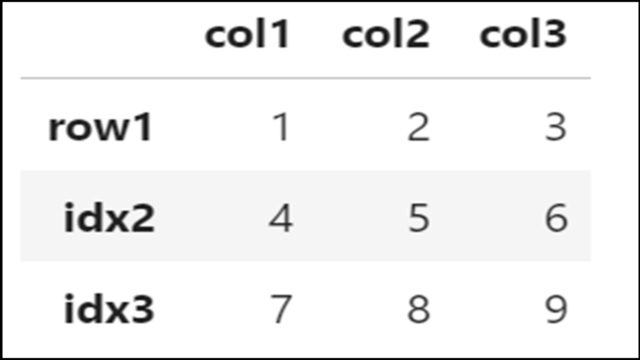
df = df.rename( index = {'idx1': 'row1'} ) |
【表示結果】
インデックス名が「idx1」から「row1」に変更されていることがわかります。
【Pythonコード】
|
1 2 3 |
df = df.rename( index = {'idx2': 'row2', 'idx3': 'row3'} ) |
【表示結果】
インデックス名が「idx2」「idx3」から「row2」「row3」に変更されていることがわかります。
まとめ
いかがでしたでしょうか。
PandasのDataFrameの作成、取得、基本情報の取得、変更について、できる限りやさしく解説してきました。
冒頭でも述べましたが、Pandasはデータ分析するために必須のライブラリとなっているため、今回のDataFrameの取り扱い方をきっちりマスターすることはとても重要です。
そして、Pandasのデータ構造にはDataFrame以外にSeriesがありましたね。
Seriesの取り扱い方についても以下の記事にまとめているので、ぜひご覧ください。
【関連記事】
【TIPS】データ分析ならコレ!Python Pandas使い方まとめ(Series編)





