【TIPS】データ分析ならコレ!Python Pandas使い方まとめ(Series編)

エンジニアライフスタイルブログを運営しているミウラ(@miumiu06171)です。
普段はフリーランスでシステムエンジニアをしております。
今回は、こちらの前回記事に引き続いて、Pythonでデータ解析の支援を行うPandasのSeries(シリーズ)操作をまとめて解説していきます。
なお、本記事内のPythonソースコードは、JupyterLabで動作を確認しているので、同様に動作確認したい方はこちらの記事も参照し、まずはJupyterLabの環境構築をおこなってください。
Seriesを作成
リスト型、辞書型、numpyでそれぞれSeriesを作成する方法を紹介していきます。
リストで作成
リスト型でSeriesを作成するには、以下のように記述します。
【Pythonコード】
リストでSeriesを作成している例です。
|
1 2 3 |
import pandas as pd s1 = pd.Series([1, 2, 3, 4, 5]) |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。

辞書型で作成
辞書型でSeriesを作成するには、以下のように記述します。
【Pythonコード】
辞書型でSeriesを作成している例です。
|
1 2 3 4 5 6 |
s1 = pd.Series( {'miura': 1, 'sato': 2, 'suzuki': 3, 'yamamoto': 4, 'tanaka': 5}) |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。

numpyで作成
numpyでSeriesを作成するには、以下のように記述します。
【Pythonコード】
numpyでSeriesを作成している例です。
|
1 2 3 |
import numpy as np s1 = pd.Series(np.arange(1, 6)) |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。

Seriesの操作
Seriesを操作する方法をまとめて紹介していきます。
Seriesのさまざまな演算
Seriesと四則演算
Seriesで四則演算(足し算、引き算、かけ算、割り算)するには、以下のように記述します。
足し算
【Pythonコード】
Seriesで足し算をしている例です。
|
1 2 3 4 5 6 7 8 |
s1 = pd.Series( {'miura': 1, 'sato': 2, 'suzuki': 3, 'yamamoto': 4, 'tanaka': 5}) s1 + 2 |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。

引き算
【Pythonコード】
Seriesで引き算をしている例です。
|
1 |
s1 - 2 |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。

かけ算
【Pythonコード】
Seriesでかけ算をしている例です。
|
1 |
s1 * 2 |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。

割り算
【Pythonコード】
Seriesで割り算をしている例です。
|
1 |
s1 / 2 |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。

Series同士の演算
Series同士の演算は、以下のように記述します。
【Pythonコード】
Series同士で足し算をしている例です。
|
1 2 3 4 5 6 7 |
s1 = pd.Series([1, 2, 3, 4, 5]) s1.index = ['miura', 'sato', 'suzuki', 'yamamoto', 'tanaka'] s2 = pd.Series([5, 8, 9, 3, 7]) s2.index = ['suzuki', 'tanaka', 'ito', 'sugawara', 'nakajima'] s1 + s2 |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。
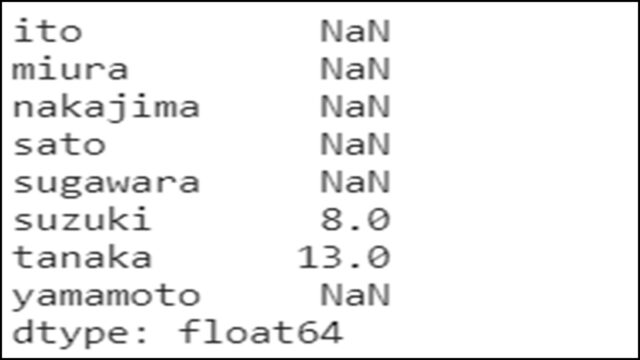
共通するインデックス(‘suzuki’と’tanaka’)がある場合、そのまま足し算で演算されていることがわかります。
一方、共通していないインデックスの場合、NaNが出力されます。
条件にマッチしたSeriesを取得
条件にマッチしたSeriesの値を取得する方法を紹介します。
条件にマッチしたものを論理値で取得
条件にマッチしたものを論理値で取得するには、以下のように記述します。
【Pythonコード】
Seriesの中で2より大きい条件にマッチしたものを論理値で取得する例です。
|
1 2 3 4 |
s1 = pd.Series([1, 2, 3, 4, 5]) s1.index = ['miura', 'sato', 'suzuki', 'yamamoto', 'tanaka'] s1 > 2 |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。

2より大きい値をもたないと「False」、2より大きい値をもつと「True」が出力されることがわかります。
条件にマッチしたものを取得
条件にマッチしたものを取得するには、以下のように記述します。
【Pythonコード】
Seriesの中で2より大きい条件にマッチしたものを取得する例です。
|
1 |
s1[s1 > 2] |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。
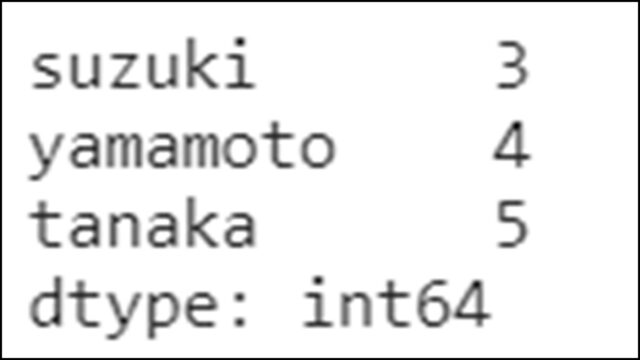
条件にマッチしたSeriesの値だけが表示されていることがわかります。
DataFrameにSeriesを追加
DataFrameにSeriesを追加する方法を紹介します。
【Pythonコード】
DataFrameの「col4」という新しいカラムにSeriesを追加する例です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
df = pd.DataFrame( [[1,2,3], [4,5,6], [7,8,9]], columns=['col1', 'col2', 'col3'], index=['idx1', 'idx2', 'idx3'] ) s1 = pd.Series( {'idx1': 11, 'idx2': 22, 'idx3': 33} ) df['col4'] = s1 |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。
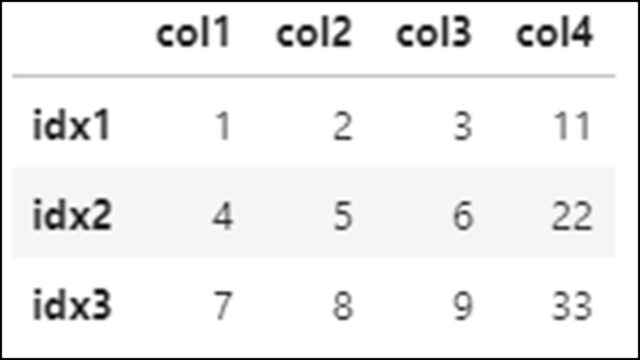
【Pythonコード】
DataFrameの「col5」という新しいカラムに、DataFrameには存在しないインデックスを含むSeriesを追加する例です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
df = pd.DataFrame( [[1,2,3], [4,5,6], [7,8,9]], columns=['col1', 'col2', 'col3'], index=['idx1', 'idx2', 'idx3'] ) s2 = pd.Series( {'idx1': 100, 'idx4': 200, 'idx5': 300} ) df['col5'] = s2 |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。
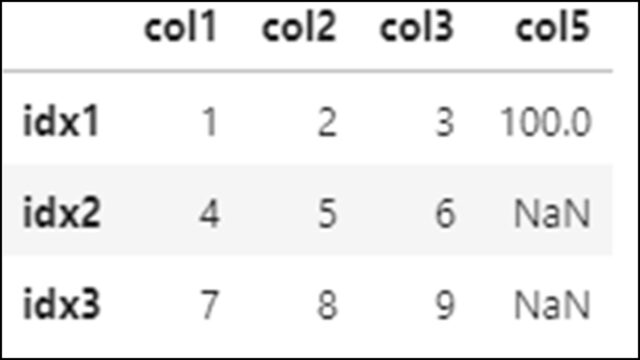
DataFrameと共通するidx1はそのままカラムに入ったが、共通ではないidx4, idx5は入らず無視されていることがわかります。
そして、DataFrameには存在しているが、追加しようとしたSeriesには存在しなかったidx2, idx3の値はNaNとして出力されます。
時系列データの追加(date_range)
時系列データを追加する方法を紹介します。
時系列データの作成
時系列データを作成するには、date_rangeメソッドを使用します。
【Pythonコード】
2021/3/12から5日間の時系列データを作成する例です。
|
1 2 3 4 |
s1 = pd.Series([1, 2, 3, 4, 5]) s1.index = ['miura', 'sato', 'suzuki', 'yamamoto', 'tanaka'] date = pd.date_range('2021/03/12', periods = 5, freq='D') |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。

時系列データの追加
時系列データをインデックスに設定するには、以下のように記述します。
【Pythonコード】
2021/3/12から5日間の時系列データをインデックスに設定する例です。
|
1 |
s1.index = date |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。

2021/3/12から2021/3/16までの時系列データがインデックスになっていることがわかります。
このように時系列データをインデックスにすることで、時系列データの表示、並び替え(ソート)、特定期間のデータを取得したりすることができるようになります。
Seriesの基本情報を取得
Seriesの基本情報を取得する方法を紹介します。
Seriesのデータを確認(values)
Seriesのデータを確認するには、valuesを使用します。
【Pythonコード】
valuesでSeriesのデータを確認する例です。
|
1 2 3 |
s1 = pd.Series([1, 2, 3, 4, 5]) s1.values |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。
|
1 |
array([1, 2, 3, 4, 5], dtype=int64) |
Seriesのデータを取得
Seriesの値を取得する方法を紹介します。
インデックス名で取得
インデックス名を指定してSeriesの値を取得するには、以下のように記述します。
【Pythonコード】
‘miura’というインデックス名を指定し、Seriesの値を取得する例です。
|
1 2 3 4 |
s1 = pd.Series([1, 2, 3, 4, 5]) s1.index = ['miura', 'sato', 'suzuki', 'yamamoto', 'tanaka'] s1['miura'] |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。
|
1 |
1 |
【Pythonコード】
‘miura’, ‘tanaka’という複数のインデックス名を指定し、Seriesの値を取得する例です。
|
1 |
s1[['miura', 'tanaka']] |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。

インデックス番号で取得
インデックス番号を指定してSeriesの値を取得するには、以下のように記述します。
【Pythonコード】
0というインデックス番号を指定し、Seriesの値を取得する例です。
|
1 |
s1[0] |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。
|
1 |
1 |
【Pythonコード】
0と4という複数のインデックス番号を指定し、Seriesの値を取得する例です。
|
1 |
s1[[0, 4]] |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。
インデックス番号0と4に対応する「miura」と「tanaka」の値が表示されていることがわかります。
Seriesのデータ型を確認(dtypes)
Seriesのデータ型を確認するには、dtypesを使用します。
【Pythonコード】
Seriesのデータ型を取得する例です。
|
1 2 3 |
s1 = pd.Series([1, 2, 3, 4, 5]) s1.dtypes |
【表示結果】
上記Pythonコードを表示すると、以下のようになります。
|
1 |
dtype('int64') |
Seriesの要素数を確認
Seriesの要素数を確認する方法を紹介します。
indexで要素数を確認
indexで要素数を確認するには、以下のように記述します。
【Pythonコード】
Seriesの要素数を確認する例です。
|
1 2 3 |
s1 = pd.Series([1, 2, 3, 4, 5]) s1.index |
【表示結果】
上記Pythonコードを表示すると、以下のようになります。
|
1 |
RangeIndex(start=0, stop=5, step=1) |
インデックス番号が0から5未満までの計5つの要素があることがわかります。
sizeで要素数を確認
sizeで要素数を確認するには、以下のように記述します。
【Pythonコード】
sizeでSeriesの要素数を取得する例です。
|
1 2 3 |
s1 = pd.Series([1, 2, 3, 4, 5]) s1.size |
【表示結果】
上記Pythonコードを表示すると、以下のようになります。
|
1 |
5 |
len関数で要素数を確認
len関数で要素数を確認するには、以下のように記述します。
【Pythonコード】
len関数でSeriesの要素数を取得する例です。
|
1 2 3 |
s1 = pd.Series([1, 2, 3, 4, 5]) len(s1) |
【表示結果】
上記Pythonコードを表示すると、以下のようになります。
|
1 |
5 |
欠損値があるか確認(hasnan)
欠損値があるか確認するには、hasnanを使用します。
【Pythonコード】
色々な記述の仕方でNoneを含むSeriesを作成し、hasnanで欠損値があるか確認している例です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import pandas as pd import numpy as np import math s1 = pd.Series([1, 2, 3, 4, 5]) s2 = pd.Series([1, 2, None, 4, 5]) s3 = pd.Series([1, 2, np.nan, 4, 5]) s4 = pd.Series([1, 2, math.nan, 4, 5]) s1.hasnans s2.hasnans s3.hasnans s4.hasnans |
【表示結果】
上記Pythonコードを表示すると、以下のようになります。
|
1 2 3 4 |
False True True True |
欠損値がある位置を確認(isnull)
欠損値がある位置を確認するには、isnullメソッドを使用します。
【Pythonコード】
Noneを含むSeriesを作成し、isnullメソッドで欠損値がある場所を確認する例です。
|
1 2 3 |
s2 = pd.Series([1, 2, None, 4, 5]) pd.isnull(s2) |
【表示結果】
上記Pythonコードを表示すると、以下のようになります。

インデックス番号が2の場所にNoneが存在することがわかります。
Seriesの基本情報を変更
Seriesの基本情報を変更する方法を紹介します。
Seriesのインデックスを変更(index)
Seriesのインデックスを変更するには、indexを使用します。
【Pythonコード】
Seriesのインデックスを変更する例です。
|
1 2 |
s1 = pd.Series([1, 2, 3, 4, 5]) s1.index = ['miura', 'sato', 'suzuki', 'yamamoto', 'tanaka'] |
【表示結果】
上記Pythonコードを表示すると、以下のようになります。

Series作成時に自動的に割り当てられた「0~4」のインデックスが変更されていることがわかります。
Seriesのインデックス名を付ける(index.name)
Seriesのインデックス名を付けるには、index.nameを使用します。
【Pythonコード】
Seriesのインデックス名を付ける例です。
|
1 |
s1.index.name = 'studentname' |
【表示結果】
上記Pythonコードを表示すると、以下のようになります。

studentnameというインデックス名が付いていることがわかります。
Seriesに名前を付ける(name)
Series全体に名前を付けるには、nameを使用します。
【Pythonコード】
Seriesの名前を付ける例です。
|
1 |
s1.name = 'studentseries' |
【表示結果】
上記Pythonコードを表示すると、以下のようになります。

studentseriesという名前が付いていることがわかります。
まとめ
いかがでしたでしょうか。
PandasのSeriesの作成、四則演算や時系列データの操作方法、基本情報の取得や変更する方法をできる限りやさしく解説してきました。
冒頭でも述べましたが、Pandasはデータ解析するために必須のライブラリとなっているため、今回のSeriesの取り扱い方もきっちりマスターしておきましょう。
【関連記事】
【TIPS】Pandasで行や列を並び替える方法まとめ(sort_values/sort_index)





