【TIPS】Pandasのgroupbyで集計する方法まとめ(サンプルコード付き)

エンジニアライフスタイルブログを運営しているミウラ(@miumiu06171)です。
普段はフリーランスでシステムエンジニアをしております。
今回は、こちらの前回記事に引き続いて、Pythonでデータ分析の支援を行うPandasのgroupby関数で集計する方法をまとめてみました。
なお、本記事内のPythonソースコードは、JupyterLabで動作を確認しているので、同様に動作確認したい方はこちらの記事も参照し、まずはJupyterLabの環境構築をおこなってください。
Pandasの集計とは
Pandasの集計とは、PandasのDataFrameにおいて列(カラム)の平均値、最大値、最小値、標準偏差などを求めることを言います。
エクセルのsumifs関数やaverageif関数、SQLのGroupBy構文の集計と同じような集計が可能です。
Pandasのおさらい
Pandasは、DataFrameというエクセルの表形式のように二次元データを持っています。
このDataFrameのデータを集計する方法を紹介していきます。
使用するDataFrameについて
まずは、本記事で使用するDataFrameを紹介します。
Pandasのgroupbyメソッドによる集計機能を紹介するために架空の売上情報を想定して作成した以下のサンプルデータを使います。
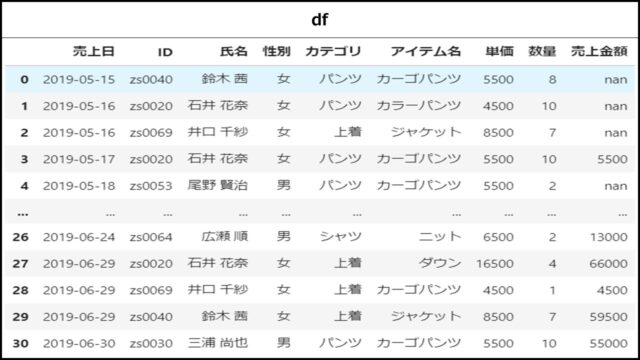
DataFrameの全体を表示
使用するDataFrameのデータは、「sample.xlsx」エクセルファイルの「売上実績_売上NaN」シートから読み込んで用意しています。
|
1 2 |
df = pd.read_excel('sample.xlsx', sheet_name='売上実績_売上NaN') df |
DataFrameの表示する列を指定
DataFrameで表示する列を指定するには、以下のようにリストで指定します。
【Pythonコード】
「氏名」列と「売上金額」列をリストで指定している例です。
|
1 |
df[['氏名', '売上金額']] |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

Pandasのgroupbyの使い方まとめ
PandasのDataFrameのデータを集計するgroupbyメソッドの使い方を紹介していきます。
特定の列で集計
特定の列で集計するには、以下のようにgroupbyメソッドの引数に列名を指定します。
【Pythonコード】
「氏名」列を指定している場合の例です。
|
1 |
df.groupby('氏名') |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
|
1 |
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001ED9712CFA0> |
上記の結果からもわかるとおり、集計結果ではなく、DataFrameGroupByオブジェクトが返ってきていることがわかります。
集計結果を得るためには、DataFrameGroupByオブジェクトで後述する集計関数を使う必要があります。
平均値を求める(mean())
groupbyメソッドで集計して平均値を求めるには、meanメソッドを使用します。
【Pythonコード】
「氏名」列でグルーピングし、「売上金額」列の平均値を出している例です。
|
1 |
df[['氏名', '売上金額']].groupby('氏名').mean() |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

合計値を求める(sum())
groupbyメソッドで集計して合計値を求めるには、sumメソッドを使用します。
【Pythonコード】
「氏名」列でグルーピングし、「売上金額」列の合計値を出している例です。
|
1 |
df[['氏名', '売上金額']].groupby('氏名').sum() |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

欠損値NaNを含めずに合計数を求める(count())
groupbyメソッドで集計して欠損値NaNを含めない合計数を求めるには、countメソッドを使用します。
【Pythonコード】
「氏名」列でグルーピングし、「売上金額」列の合計数を出している例です。
|
1 |
df[['氏名', '売上金額']].groupby('氏名').count() |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

上記の合計数には、売上金額が欠損値NaNとなっている行は含まれていません。
売上金額がNaNの行も合計数にカウントする場合は、次のsizeメソッドを使用します。
欠損値NaNを含めた合計数を求める(size())
groupbyメソッドで集計して欠損値NaNを含めた合計数を求めるには、sizeメソッドを使用します。
【Pythonコード】
「氏名」列でグルーピングし、「売上金額」列の合計数を出している例です。
|
1 |
df[['氏名', '売上金額']].groupby('氏名').size() |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

上記の合計数には、売上金額が欠損値NaNとなっている行も含まれています。
グループの中でN番目のデータを取得(nth(N))
groupbyメソッドで集計してN番目のデータを求めるには、nthメソッドを使用します。
【Pythonコード】
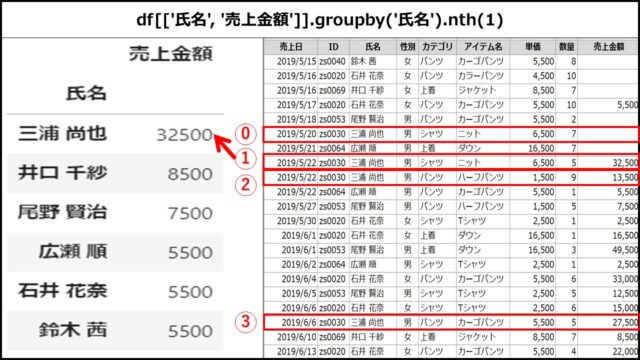
「氏名」列でグルーピングし、「売上金額」列の1番目のデータを出している例です。
|
1 |
df[['氏名', '売上金額']].groupby('氏名').nth(1) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
【Pythonコード】
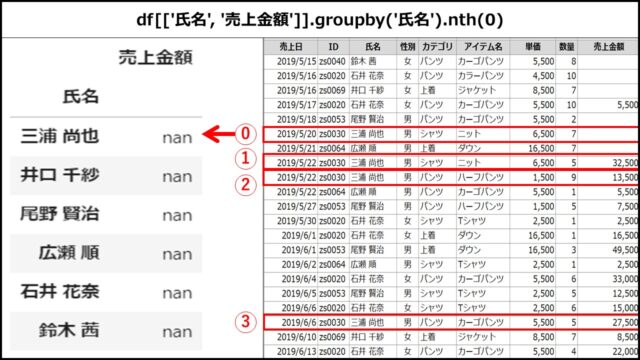
「氏名」列でグルーピングし、「売上金額」列の0番目のデータを出している例です。
|
1 |
df[['氏名', '売上金額']].groupby('氏名').nth(0) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
最大値を求める(max())
groupbyメソッドで集計して最大値を求めるには、maxメソッドを使用します。
【Pythonコード】
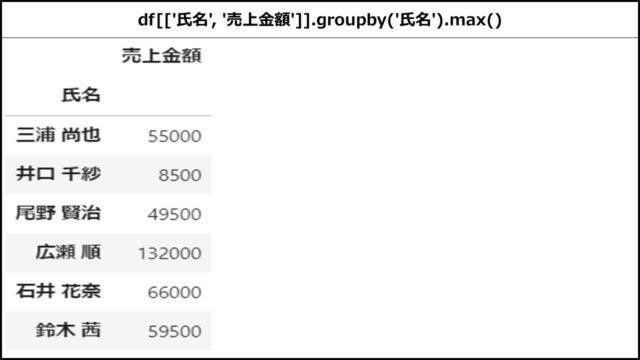
「氏名」列でグルーピングし、「売上金額」列の最大値を出している例です。
|
1 |
df[['氏名', '売上金額']].groupby('氏名').max() |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
最小値を求める(min())
groupbyメソッドで集計して最小値を求めるには、minメソッドを使用します。
【Pythonコード】
「氏名」列でグルーピングし、「売上金額」列の最小値を出している例です。
|
1 |
df[['氏名', '売上金額']].groupby('氏名').min() |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

中央値を求める(median())
groupbyメソッドで集計して中央値を求めるには、medianメソッドを使用します。
【Pythonコード】
「氏名」列でグルーピングし、「売上金額」列の中央値を出している例です。
|
1 |
df[['氏名', '売上金額']].groupby('氏名').median() |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

標準偏差を求める(std())
groupbyメソッドで集計して標準偏差を求めるには、stdメソッドを使用します。
【Pythonコード】
「氏名」列でグルーピングし、「売上金額」列の標準偏差を出している例です。
|
1 |
df[['氏名', '売上金額']].groupby('氏名').std() |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

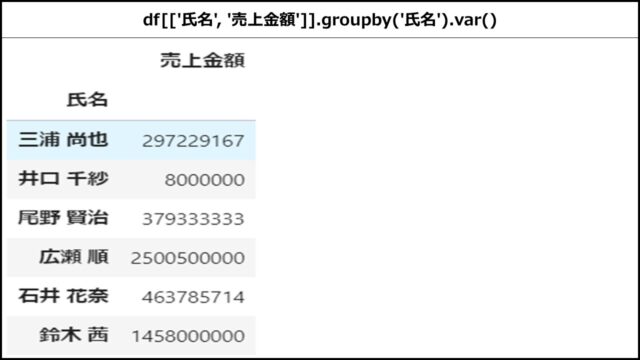
分散を求める(var())
groupbyメソッドで集計して分散を求めるには、varメソッドを使用します。
【Pythonコード】
「氏名」列でグルーピングし、「売上金額」列の分散を出している例です。
|
1 |
df[['氏名', '売上金額']].groupby('氏名').var() |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
複数列でグルーピングして集計
複数列でグルーピングして集計するには、以下のようにgroupbyメソッドの引数にリストで列名を複数指定します。
グルーピングした複数列をインデックスにして集計
複数列でグルーピングするには、groupbyメソッドの引数にリストで複数列名を指定します。
【Pythonコード】
「氏名」「カテゴリ」列でグルーピングし、「売上金額」列の平均値を出している例です。
|
1 |
df[['氏名', 'カテゴリ', '売上金額']].groupby(['氏名', 'カテゴリ']).mean() |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

グルーピングした複数列をインデックスにせず集計
複数列でグルーピングするが、インデックスとはしないようにするには、groupbyメソッドの引数as_indexを使用します。
【Pythonコード】
複数列でグルーピングするが、インデックスとしないように「as_index=False」を使用している例です。
|
1 |
df[['氏名', 'カテゴリ', '売上金額']].groupby(['氏名', 'カテゴリ'], as_index=False).mean() |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

aggメソッドで集計
aggメソッドでより柔軟に集計する方法を紹介していきます。
aggメソッドの基本的な使い方
aggメソッドの基本的な使い方は、以下のとおりです。
【Pythonコード】
「氏名」列でグルーピングし、「売上金額」列の平均値を出している例です。
|
1 |
df[['氏名', '売上金額']].groupby('氏名').agg('mean') |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
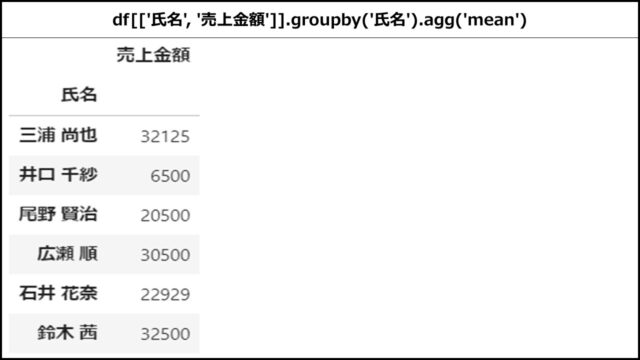
aggメソッドの引数に集計関数名を指定すると、平均値を出力できていることがわかります。
【Pythonコード】
「氏名」列でグルーピングし、「数量」「売上金額」列の平均値を出している例です。
|
1 |
df[['氏名', '数量', '売上金額']].groupby('氏名').agg('mean') |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
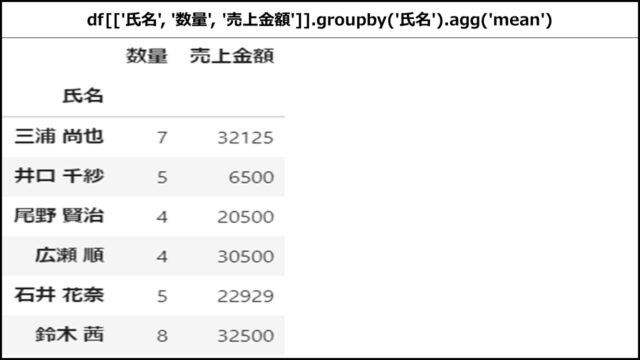
aggメソッドの引数に集計関数名を指定すると、「数量」列と「売上金額」列の平均値を出力できていることがわかります。
aggメソッド内で集計関数をリストで指定
aggメソッド内で集計関数をリストで指定することで、複数の集計結果を表示することができます。
【Pythonコード】
「氏名」列でグルーピングし、「数量」「売上金額」列の平均値と合計値を出している例です。
|
1 |
df[['氏名', '数量', '売上金額']].groupby('氏名').agg(['mean', 'sum']) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
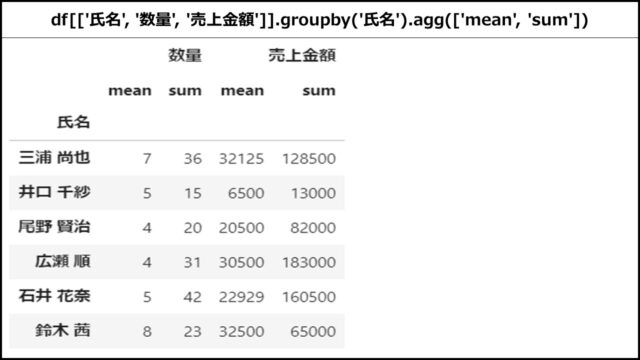
「数量」「売上金額」列のそれぞれについて、平均値と合計値が表示されていることがわかります。
「数量」列は合計値のみ、「売上金額」列は平均値と合計値を出すように柔軟に表示結果を変えたい場合は、次の辞書型で指定する方法がとても便利です。
aggメソッド内で集計関数を辞書型で指定
aggメソッドの引数に列名をKey、集計関数をValueとする辞書型を指定することで、集計結果を柔軟に指定することができます。
【Pythonコード】
「数量」の合計値、「売上金額」の平均値と合計値の計3つを表示する例です。
|
1 |
df[['氏名', '数量', '売上金額']].groupby('氏名').agg({'数量': ['sum'], '売上金額': ['mean', 'sum']}) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
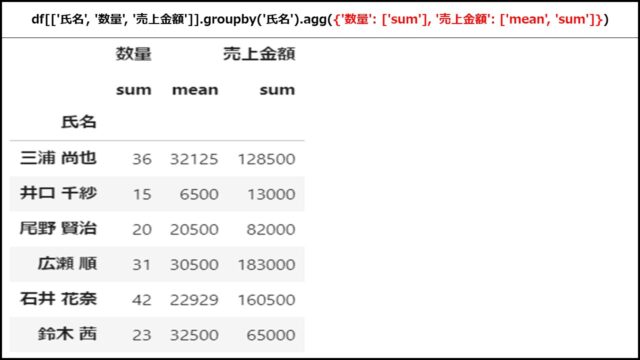
「数量」列は合計値のみ、「売上金額」列は平均値と合計値を出していることがわかります。
aggメソッド内で独自関数を辞書型で指定
aggメソッド内で指定する集計関数として独自関数を指定する方法を紹介します。
独自関数を外部に定義するパターン
外部に定義している独自関数を呼び出すためには、以下のように辞書型のValueに関数名を指定します。
【Pythonコード】
消費税込みの売上金額を求める独自関数calc_taxを呼び出す例です。
|
1 2 3 4 |
def calc_tax(s): return np.sum(s) * 1.10 df[['氏名', '売上金額']].groupby('氏名').agg({'売上金額': calc_tax}) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
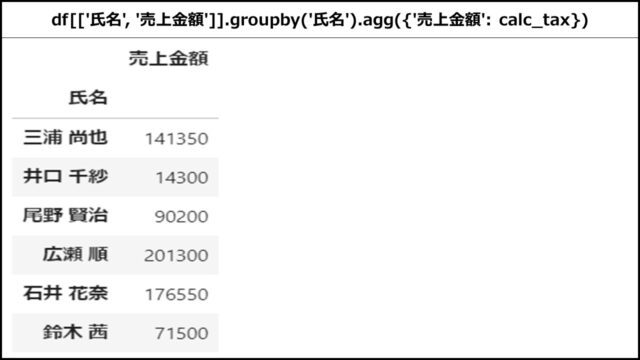
aggメソッド内に売上金額をKey、独自関数calc_taxをValueとする辞書型を指定することで、税込みの総売上金額が表示されていることがわかります。
独自関数をlambdaで定義するパターン
先程の独自関数をlambdaで定義する方法を紹介します。
【Pythonコード】
独自関数をlambdaで定義する例です。
|
1 |
df[['氏名', '売上金額']].groupby('氏名').agg({'売上金額': lambda s : np.sum(s) * 1.10}) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

辞書型のValueにlambdaで関数定義することで、同じように独自関数を使用することができます。
まとめ
いかがでしたでしょうか。
Pandasの集計を行うgroupbyメソッドの使い方をみてきました。
groupbyメソッドの使い方を理解できれば、毎週・毎月行っている売上レポートなどを自動化することもできます。
そして、Pandasにはエクセルのピボットテーブルのような機能も備えているので、一緒に学びながら自分の仕事に活かすことも考えていきましょう。





