【TIPS】Pandasで行や列を並び替える方法まとめ(sort_values/sort_index)

エンジニアライフスタイルブログを運営しているミウラ(@miumiu06171)です。
普段はフリーランスでシステムエンジニアをしております。
今回は、こちらの前回記事に引き続いて、Pythonでデータ解析の支援を行うPandasのDataFrameやSeriesの並び替え(ソート)操作をまとめて解説していきます。
なお、本記事内のPythonソースコードは、JupyterLabで動作を確認しているので、同様に動作確認したい方はこちらの記事も参照し、まずはJupyterLabの環境構築をおこなってください。
DataFrame(データフレーム)の並び替え
DataFrameを並び替える方法を紹介していきます。
データ要素でソート(sort_values)
DataFrameのデータ要素でソートするには、sort_valuesメソッドを使用します。
sort_valuesメソッドの詳細については、こちらのPandas公式ドキュメントを参照してください。
列方向でデータソート
DataFrameのデータ要素を列方向でソートするには、以下のように記述します。
昇順でソート(ascending=True)
【Pythonコード】
「sample.xlsx」の「売上実績」シートからデータを取り込んだ後、カラム名「売上金額」を元にデータを昇順でソートしている例です。
|
1 2 3 4 5 6 7 8 |
import pandas as pd pd.set_option('display.max_columns', None) pd.set_option('display.max_rows', 8) df = pd.read_excel('sample.xlsx', sheet_name='売上実績') df.sort_values(by='売上金額', ascending=True) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
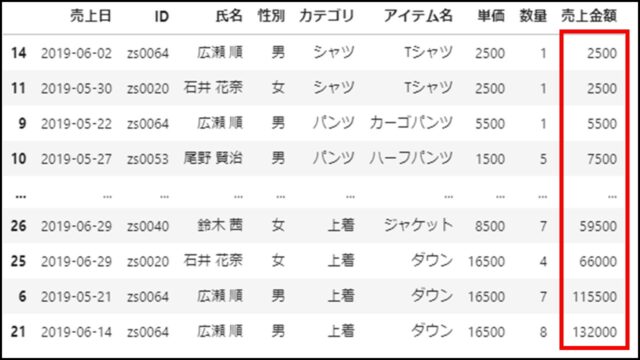
カラム名「売上金額」のデータ要素が昇順にソートされたことがわかります。
降順でソート(ascending=False)
【Pythonコード】
カラム名「売上金額」を元にデータを降順でソートしている例です。
|
1 |
df.sort_values(by='売上金額', ascending=False) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
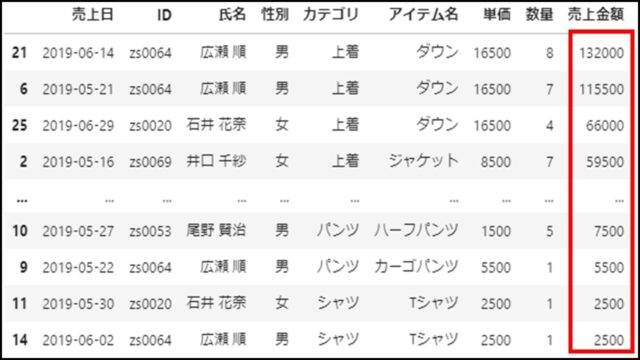
カラム名「売上金額」のデータ要素が降順にソートされたことがわかります。
複数列でデータソート(sort_values)
複数列(カラム)でデータをソートする方法を紹介します。
複数列をすべて昇順でソートする場合
指定した複数列をすべて昇順でソートするには、以下のように記述します。
【Pythonコード】
カラム名「氏名」「売上金額」の複数列でデータをソートしている例です。
|
1 |
df.sort_values(by=['氏名', '売上金額']) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
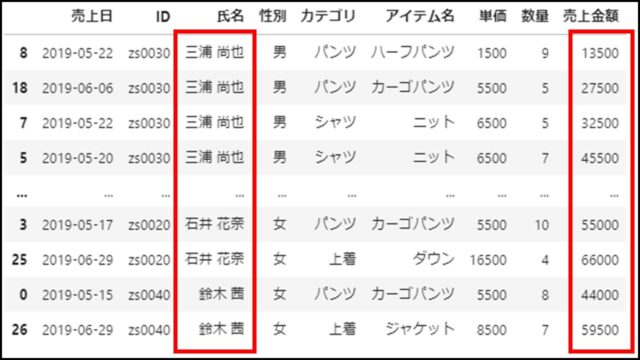
「氏名」「売上金額」の複数列が昇順でソートされたことがわかります。
複数列の並び替え順序をそれぞれ指定してソートする場合
複数列の並び替え順序をそれぞれ指定してソートするには、以下のように記述します。
【Pythonコード】
カラム名「氏名」は昇順、「売上金額」は降順でデータをソートしている例です。
|
1 |
df.sort_values(by=['氏名', '売上金額'], ascending=[True, False]) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
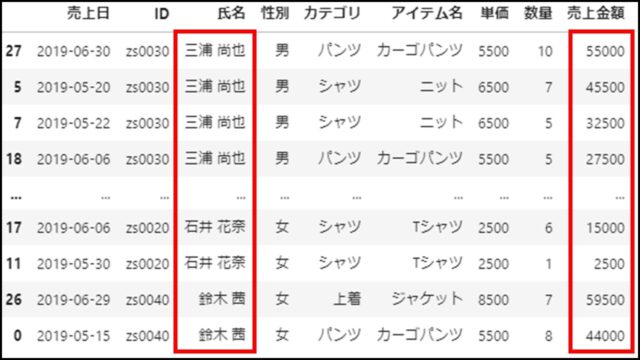
「ascending」に並び替え順序をリストで指定することで、「氏名」は昇順、「売上金額」は降順でデータ要素がソートされていることがわかります。
欠損値NaNを含むデータソート(na_position)
欠損値NaNを含むデータをソートする方法を紹介していきます。
ソート時に欠損値NaNを最下行にまとめる
【Pythonコード】
カラム名「氏名」で欠損値NaNを含むデータを昇順にソートし、NaNを最下行にまとめる例です。
|
1 2 3 4 5 6 7 8 |
import pandas as pd pd.set_option('display.max_columns', None) pd.set_option('display.max_rows', 8) df = pd.read_excel('sample.xlsx', sheet_name='売上実績_NaN') df.sort_values(by='氏名', ascending=True) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
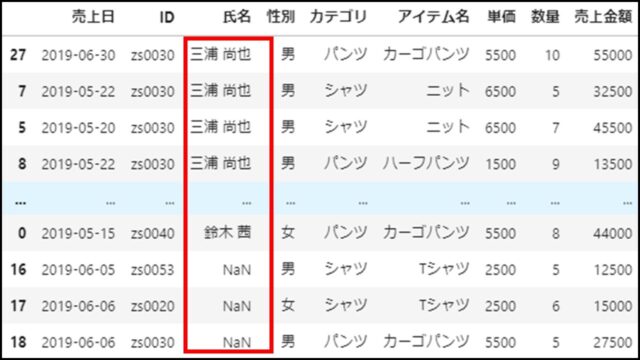
欠損値NaNは、最下行にまとめられていることがわかります。
「ascending=True」の昇順を例にしましたが、「ascending=False」の降順で実行しても同様に欠損値NaNは最下行にまとめられます。
ソート時に欠損値NaNを先頭にまとめる
【Pythonコード】
カラム名「氏名」で欠損値NaNを含むデータを昇順にソートし、NaNを先頭にまとめる例です。
先程と違って「na_position=’first’」が引数に追加されています。
|
1 |
df.sort_values(by='氏名', ascending=True, na_position='first') |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
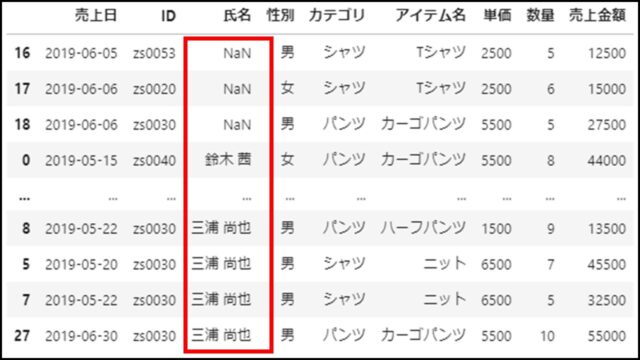
「na_position=’first’」を指定することで、欠損値NaNは先頭にまとめられていることがわかります。
ソートした結果で元のDataFrameを上書き(inplace)
ソート時にソートした結果で元のDataFrameを上書きするには、以下のようにinplaceを使用します。
【Pythonコード】
カラム「col1」のデータを元に降順でソートした結果でDataFrameを上書きしている例です。
|
1 2 3 4 5 6 7 8 |
df_ax = pd.DataFrame( {'col1': [1, 5, 9], 'col2':[2,4,8], 'col3': [3,6,7]}, index=['idx1', 'idx2', 'idx3']) print(df_ax) df_ax.sort_values(by='col1', ascending=False, inplace=True) print(df_ax) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

カラム「col1」のデータ要素を元に降順でソートされていることがわかります。
行方向でデータソート(axis)
DataFrameのデータ要素を行方向でソートするには、以下のようにaxisを使って記述します。
【Pythonコード】
「idx1」の行方向でデータを降順でソートする例です。
|
1 2 3 4 5 |
df_ax = pd.DataFrame( {'col1': [1, 5, 9], 'col2': [2,4,8], 'col3': [3,6,7]}, index=['idx1', 'idx2', 'idx3']) df_ax.sort_values(by='idx1', ascending=False, axis=1) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
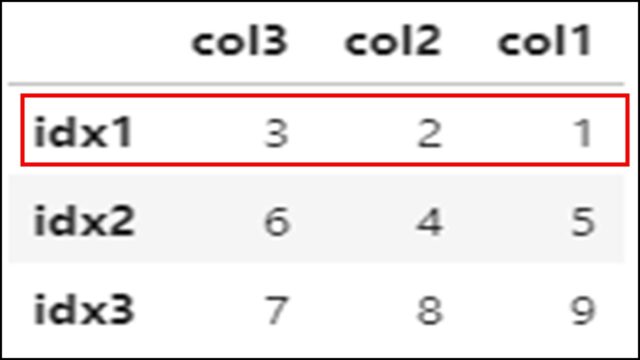
「idx1」の行方向でデータ要素が降順でソートされていることがわかります。
インデックス(行名・列名)でソート(sort_index)
インデックスでソートするには、sort_indexメソッドを使用します。
sort_indexメソッドの詳細については、こちらのPandas公式ドキュメントを参照してください。
行名でソート(axis=0)
行名でソートするには、以下のように記述します。
【Pythonコード】
行名を降順でソートする例です。
|
1 2 3 4 5 |
df_ax = pd.DataFrame( {'col1': [1, 5, 9], 'col2':[2,4,8], 'col3': [3,6,7]}, index=['idx1', 'idx2', 'idx3']) df_ax.sort_index(ascending=False) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

行名が降順でソートされていることがわかります。
このとき、元のDataFrameは上書きされません。
【Pythonコード】
DataFrameを上書きするには、sort_valuesメソッドと同様に「inplace=True」を使用することができます。
|
1 |
df_ax.sort_index(ascending=False, inplace=True) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。
「inplace=True」を指定しているため、元のDataFrameは行名を降順でソートされたデータで上書きされます。
【Pythonコード】
欠損値NaNの取り扱いについてもsort_valuesメソッドと同様に「na_position」を使用することができます。
|
1 |
df_ax.sort_index(ascending=False, inplace=True, na_position='first') |
【表示結果】
今回欠損値NaNは含まれていないが、「na_position=’first’」も同様にNaNが含まれていたら、行頭に表示されるようになります。
列名でソート(axis=1)
列名でソートするには、以下のように記述します。
【Pythonコード】
列名を降順でソートする例です。
|
1 2 3 4 5 |
df_ax = pd.DataFrame( {'col1': [1, 5, 9], 'col2':[2,4,8], 'col3': [3,6,7]}, index=['idx1', 'idx2', 'idx3']) df_ax.sort_index(axis=1, ascending=False) |
【表示結果】
上記PythonコードのDataFrameを表示すると、以下のようになります。

列名が降順でソートされていることがわかります。
Series(シリーズ)の並び替え
Seriesを並び替える方法を紹介していきます。
データ要素でソート(sort_values)
Seriesのデータ要素でソートする方法を紹介します。
【Pythonコード】
DataFrameから「col1」というSeriesを取得した後、昇順でデータをソートする例です。
|
1 2 3 4 5 6 7 |
df_ax = pd.DataFrame( {'col1': [5, 1, 9], 'col2':[2,4,8], 'col3': [3,6,7]}, index=['idx1', 'idx2', 'idx3']) s = df_ax['col1'] s.sort_values(ascending=True) |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。

「col1」のデータ要素が昇順にソートされていることがわかります。
インデックス(行名・列名)でソート(sort_index)
インデックスでソートする方法を紹介します。
【Pythonコード】
DataFrameから「col1」というSeriesを取得した後、行名を降順でソートする例です。
|
1 2 3 4 5 6 7 |
df_ax = pd.DataFrame( {'col1': [5, 1, 9], 'col2':[2,4,8], 'col3': [3,6,7]}, index=['idx1', 'idx2', 'idx3']) s = df_ax['col1'] s.sort_index(ascending=False) |
【表示結果】
上記PythonコードのSeriesを表示すると、以下のようになります。
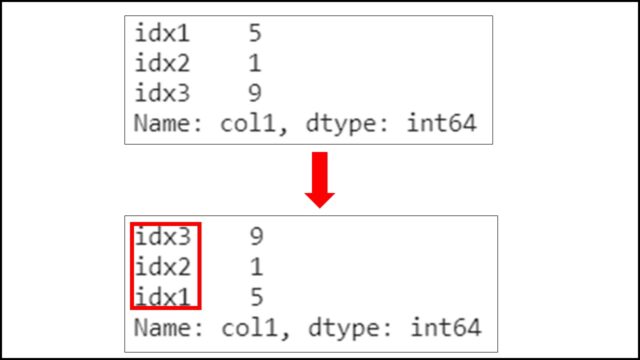
行名が降順でソートできていることがわかります。
まとめ
いかがでしたでしょうか。
PandasのDataFrameやSeriesを並び替える方法をみてきました。
Pandasでデータを結合後に並び替え機能をよく使うので、ぜひこの機会にマスターして頂ければと思います。
【関連記事】
【TIPS】Pandasのmerge関数でDataFrameを結合する方法まとめ
【TIPS】Pandasのconcat関数でDataFrameを結合する方法まとめ





